
Share



BigQuery Machine Learning (BQML) can train and serve ML models using SQL to power marketing automation and help deliver personalized experiences.
Article Series Overview
In the "Use BQML to Activate Audiences on Google Marketing Platform (GMP)" article series, we'll use unsupervised machine learning methods to build clusters of users grouped by their similarities to each other. We'll analyze these clusters to extract insights and add meaningful business labels to understand them better. Then we'll load these clusters into Google Analytics using the Management API to turn them into segments, and finally, we'll build GA Audiences to activate these users across the GMP.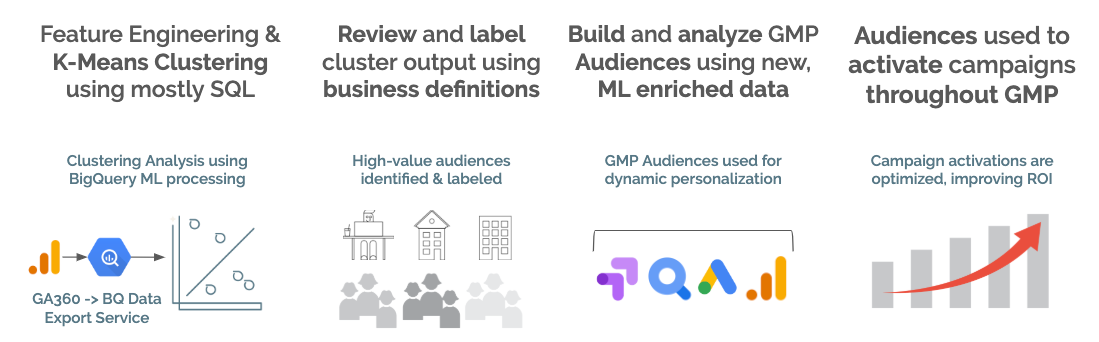
Technologies We'll Use
- Google Cloud
- BigQuery (link to more information)
- Dataprep (link)
- Google Marketing Platform (link)
The Business Challenge to Solve
Digital analysts often find themselves drilling further and further into the GA data model, trying to isolate groups of users and compare their performance metrics to other groups of users. This process is time-consuming and risks missing critical information — the signal buried underneath the noise — thereby corrupting the analysis. Machine Learning offers a way to sort through dozens or hundreds of dimensional permutations and group together users based on their similarities and does this at a scale and fidelity any single analyst would have trouble replicating on their own. The digital analytics world has come face to face with the same problem John Henry ran into many years ago: The teams that embrace automation and transition from the hammer to the machine will be the ones prepared for the future that has already arrived.Technical Solutions Covered
At Adswerve, we've been working with the GA Data Model in BigQuery since the GA360 GA Export was first enabled. We've learned a thing or two and have established best practices around preparing that data for machine learning processing, and this is a summary of our general approach: Any machine-learning development life cycle follows a general pattern:-
- Data Preparation: build a repeatable pipeline to clean and transform data
- Modeling: ML engineers tune features to improve model performance
- Deployment: deploy the model to a production environment to serve new predictions
- Monitoring: track model performance against goals, monitor solution SLOs
Creating Business Value
Machine Learning data pipelines help companies transition from descriptive to predictive analytics solutions. The tools being released by Google in the form of BigQuery ML, and others, make it possible for your marketing teams to take advantage of ML processing without having to hire from a limited pool of machine learning engineers. The speed at which you use data to return value to your business dramatically increases when used in predictive machine learning data pipelines. Finally, all industries are investing heavily in this type of analysis. The machines have already arrived, your competitors are using them as you read this, it is easier than ever to get started, and that is what this series aims to help you achieve. Ready for more?Check out the first article "Data Preparation" to continue learning about how you can use BQML to activate audiences on Google Marketing Platform.Are you looking for more information about anything mentioned in this article? Please contact us with any questions.
